



Intel Sandy Bridge处理器抢先预览
 随着Intel旧金山秋季IDF 2010的召开,Intel下一代处理器Sandy Bridge的神秘面纱被逐渐揭开。那么这一被Intel寄予厚望的处理器在技术架构上将有怎样的改变?性能会得到多大的提升?请看本刊为您带来的抢鲜报道。
随着Intel旧金山秋季IDF 2010的召开,Intel下一代处理器Sandy Bridge的神秘面纱被逐渐揭开。那么这一被Intel寄予厚望的处理器在技术架构上将有怎样的改变?性能会得到多大的提升?请看本刊为您带来的抢鲜报道。
自1968年创立以来,Intel始终都站在微处理器行业的领袖地位上,也一直是先进微处理器技术的象征和标志,近几年更是凭借不停歇的Tick-Tock交替发展策略牢牢占据着技术和市场的主动权。如今随着2011年的临近、Intel旧金山秋季IDF 2010的召开,Intel下一代处理器架构Sandy Bridge也正在揭开神秘面纱。在AMD积极准备推土机(Bulldozer)、山猫(Bobcat)两套全新架构、试图全面反击的关头,Sandy Bridge肩上的重担不言自明,那么这个全新架构到底新在何处?技术和特性方面有什么过人的地方?实际性能表现又是如何呢?下面,就让我们首先通过Intel全球副总裁兼架构事业部总经理浦大卫先生在秋季IDF 2010上的讲解,来看看Sandy Bridge会给您留下怎样的第一印象。
四大进化助腾飞 Sandy Bridge架构深入解析
Intel宣称Sandy Bridge采用了全新设计的微架构,属于Tick-Tock发展策略中的Tock环节。

在旧金山秋季IDF 2010上,浦大卫对Sandy Bridge的技术架构进行了详细的解析。
不过从浦大卫先生的讲解来看,Sandy Bridge并不是彻底从零开发的革命性产品,本质上和现有架构仍有很多相同之处,但通过在以下四个方面的完善和增强,带来了性能上的明显进步。
1.整合物理寄存器堆 提升浮点运算能力
类似于AMD的推土机、山猫架构,Sandy Bridge也使用了物理寄存器堆(Physical Register File),这个功能块起的主要作用是节约功耗。所有微指令运算数据将存储在物理寄存器堆里,而无需带入乱序执行引擎里。当乱序执行引擎需要使用这些数据时,只需从微指令找到这些数据的对应指针即可。因此可以显著降低乱序执行硬件的功耗(如将大量数据转移则会产生较大的功耗),以及处理器核心面积。而核心面积的精简则为Sandy Bridge提升AVX指令集运算性能创造了条件。

物理寄存器堆的使用为降低功耗、提高乱序执行引擎缓存创造了条件。
我们知道,AVX指令集将计算位宽由128-bit提升到256-bit,一次计算就可以处理更多的数据。但要实现AVX指令集则需要处理器硬件上的配合。得益于物理寄存器堆的使用,Sandy Bridge处理器可以将更多的晶体管用在关键的运算单元里,其中所有的SIMD浮点运算单元计算位宽由传统处理器的128-bit升级到256-bit。同时,由于浮点运算单元吞吐量的增大,乱序执行引擎也采用了更大的缓存空间予以配合。此外,Sandy Bridge的整数执行单元也有一定改进,如ADC指令吞吐量翻番、乘法运算加速25%。
2.颠覆内部结构 环形总线显威力
在Nehalem/Westmere等现有Intel处理器中,每个核心都与三级缓存单独相连,各自需要大约1000条连线,这种情况下如果频繁访问三级缓存,就可能出现问题。而对于整合了GPU图形核心、视频转码引擎的Sandy Bridge来说,如果沿用这样的做法还得再增加多达2000条连线。为此Sandy Bridge引入了早在Nehalem EX与Westmere EX服务器处理器上使用的环形总线(Ring Bus),每个核心、每一区块三级缓存(LLC)、集成图形核心、媒体引擎、系统助手(即处理器北桥功能部分)在这条总线上都拥有自己的接入点,形象地说就是多个“停靠站台”。

环形总线带来的大好处是让每一个功能部分都可随时访问三级缓存,降低延迟,并提升数据吞吐带宽。
采用环形总线的大好处是可以降低每个核心访问三级缓存的延迟,并提升三级缓存的数据吞吐带宽。Intel现有处理器的每个核心要访问三级缓存时,都必须通过一条缓存流水线发出请求,经过优先级排序后才能依次访问。而在Sandy Bridge中,则将三级缓存划分成多个区块,并分别对应每一个CPU核心。因此每个核心都可以随时访问全部三级缓存,其延迟从36个周期减少到26~31个周期。同时,Sandy Bridge每个核心与三级缓存间的数据带宽为96GB/s,因此四核心Sandy Bridge的三级带宽可以达到惊人的96GB/s×4=384GB/s。
此外三级缓存的频率也开始和处理器核心频率同步,因而速度更快,缺点就是三级缓存也会随着处理器核心降频而降频。所以如果处理器降频的时候,图形核心又正好需要访问三级缓存,那么低速的三级缓存就会影响图形核心的性能。
3.可共享三级缓存 图形核心性能提升大
Sandy Bridge集成的GPU图形核心主要由新的EU可编程着色硬件组成,它包含着色器、核心、执行单元等。与当前Intel集成显示核心使用的EU相比,Sandy Bridge里的EU拥有更大的寄存器文件,并采用第二代并行分支,提升了执行并行任务与复杂着色指令的能力。同时,超越数学运算交由EU内的硬件负责,其直接好处是大大提升了正弦(sin)、余弦(cos)等函数的运算速度。此外,EU内部采用类似CISC的架构设计,DirectX 10 API指令与其内部指令一一对应,可有效提高工作效率,在每个时钟周期,EU可完成更多的指令。经过以上改进,新型EU的指令吞吐量比在Clarkdale里使用的EU提升了两倍。

通过采用更大的寄存器文件、第二代并行分支等四大改进,EU的性能较上代产品提升了两倍。
同时,得益于环形总线的采用,Sandy Bridge图形核心还将获得另外一个好处。可以通过“接入点”共享三级缓存。显卡驱动会控制访问三级缓存的权限,甚至可以限制GPU使用多少缓存。将图形数据放在缓存里,图形核心就不用绕道去拜访遥远而缓慢的内存了,这对提升性能、降低功耗都大有裨益。
此外,在工艺上,新一代图形核心也有明显进步。现在的Clarkdale虽然也集成了图形核心,但采用的是CPU+GPU的双内核封装,制造工艺也是相对落后的45nm。而Sandy Bridge则将CPU、GPU封装在同一内核中,并全部采用32nm工艺。资料显示,Sandy Bridge集成的GPU图形核心分为两种版本,分别拥有6个、12个EU。首批发布的移动版处理器将全部集成12个EU,桌面版则根据型号不同而有两种配置。唯一的遗憾是,该核心仍停留在DirectX 10时代,要想支持DiretctX 11,则得等到下一代22nm工艺的Ivy Bridge。
4、睿频技术加入GPU 外频超频能力下降
从Sandy Bridge开始,Intel处理器的睿频技术将不只包括处理器,图形核心也将加入进来。图形核心将在占用率较高的游戏或图形程序中自动提高频率,增强性能。当然,如果软件需要更多CPU资源,那么CPU就会加速、GPU同时减速。从英特尔Sandy Bridge桌面处理器泄露的规格来看,每款Sandy Bridge处理器都将具备这个特性,其图形核心默认频率后都跟有一个动态频率参数。其中Core i7 2600K的图形核心在开启动态频率调节后,频率可由默认的850MHz上升到1350MHz,频率提升幅度达58%,远远超过了目前任何一款整合图形核心的工作频率。这说明处理器的制程工艺更新也让图形核心受益匪浅。
不过尽管睿频技术得到较大发展,但让人遗憾的是,普通Sandy Bridge处理器的超频能力将大幅下降。这主要是由于Sandy Bridge处理器内部集成的时钟发生器体质不佳,外频(BCLK)只能工作在100MHz左右,因此通过外频进行大幅超频的可能性几乎为零。想对Sandy Bridge进行超频的用户只能选购未锁倍频的K版处理器。
王者君临天下 Sandy Bridge性能测试预览
接下来就让我们通过国外曝光的性能测试,来了解本次Sadny Bridge处理器的真实性能。测试中将采用一颗Core i5 2400工程样品,并搭配一块H67芯片组主板。
表1:测试平台
| 主板 | 华硕P7H57DV-EVO (Intel H57) Intel DP55KG (Intel P55) Intel DX58SO (Intel X58) Intel DX48BT2 (Intel X48) 技嘉GA-MA790FX-UD5P (AMD 790FX) |
| 内存 | 海盗船DDR3-1333 1GB×4 (7-7-7-20) 海盗船DDR3-1333 2GB×2 (7-7-7-20) |
| 硬盘 | Intel X25-M 80GB |
| 显卡 | EVGA GeForce GTX 280 ATI Radeon HD 5870 |
由于样品的缘故,该处理器关闭了睿频加速技术,但同时也提供了Core i5系列不应支持的超线程技术,因此测试过程中会考察处理器开启和关闭超线程两种情况下的不同表现。此外,由于Intel目前暂未公开桌面级处理器的图形核心细节,因此无法确定该处理器拥有多少个EU。
匹敌Radeon HD 5450 集成图形核心性能测试
从测试来看,在硬件和驱动程序都还极不完善的情况下,Sandy Bridge图形核心性能相比现有的Intel集成显示核心提升幅度达到了220%以上,更完全超越了AMD 890GX/790GX这两款强大的整合芯片组,甚至比AMD入门级独立显卡Radeon HD 5450都还要强一些,在游戏中获得了很好的运行流畅度。



这说明对图形核心EU单元的改进、环形总线的加入、三级缓存的共享对图形核心性能的提升是切实有效的。
超越Core i7 880 处理器游戏性能测试
接下来,通过搭配高端独立显卡Radeon HD 5870,测试了处理器的游戏性能。测试显示,Core i5 2400虽然定位不算高,但也完全不会成为游戏瓶颈,实际速度不仅全面超越Core i7 880、Core i5 760,甚至在不少时候都能和频率更高、核心更多的Core i7 980X Extreme一较高低。



对游戏玩家来说,Sandy Bridge毫无疑问是个福音。
4>8 处理器运算性能测试
测试成绩令人惊喜,在数据恢复测试中Core i5 2400只用4核心、4线程就能超过4核心、8线程的Core i7 880,甚至12线程的Core i7 980X。这说明全新的分支引擎、环形总线的引入、增强的浮点运算单元的确有效提高了Sandy Bridge处理器单个核心的运算性能,因此能做到以少胜多也就并不让人意外。




所以从打开超线程后的Core i5 2400测试来看,那些支持超线程技术的Core i7 Sandy Bridge处理器将拥有更加让人期待的性能。
第二代32nm显神威 处理器功耗测试
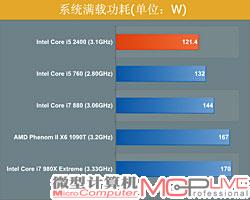
Sandy Bridge的性能有了大幅度的提升,功耗是否也会同步增加呢?事实上这样的担心是多余的。Sandy Bridge虽然还是32nm制造工艺,但已经进化到第二代,还有更成熟的高K金属栅极(HKMG)技术做保障,其待机情况下的系统功耗和Core i5 760/Core i7 880几乎完全相同,并远远低于六核心型号,而满载功耗更是参测系统中低的,优势一目了然。
性能提升令人喜 MC全面测试将登场
综合来看,除了图形核心性能大幅提升以外,Core i5 2400的处理器运算性能相比Core i5 760也有23%之多。对比更高端的Core i7 880,即使无法开启超线程也不会逊色多少,在有些软件中甚至还会更快。

换算下来,同等频率下,Sandy Bridge架构的处理器运算性能提升幅度应该有10%左右,但是请记住,这里还没有开启睿频动态加速,终零售版估计还能借此再提升3%~7%。因此想知道Sandy Bridge处理器开启动态加速后的真实性能吗?想了解Sandy Bridge处理器对于外频超频是否真的无能为力?想获得更全面的Sadny Bridge处理器使用体验报告吗?尽请期待《微型计算机》评测室即将于近期推出的Sadny Bridge处理器全面测试。
Sandy Bridge处理器实物抢先看

《微型计算机》评测室获得的三颗Sandy Bridge处理器,从正面来看,LGA 1155处理器与LGA 1156处理器几乎完全相同。

但从处理器背面来看,Sandy Bridge处理器(中)背面的电容和电阻数量与排列方式上与Clarkdale(左)与Lynnfield(右)都存在明显不同。

LGA 1155处理器(下)缺口位到处理器末端的长度略大于LGA 1156处理器(上)。

